Building a Cloud Managed Hypervisor
The story of how we built our product and the most interesting problems [so far]
October 7th - 2023Richard Stephens - Co-Founder
Cloud Whisperer
David Tisdall - Co-Founder
Reformed Sysadmin
Background
Gallium is a Cloud-Managed Hypervisor that brings a AWS-like experience to running workloads on your own servers. We built Gallium to address on-prem application needs and to allow larger cloud customers to move workloads onto cheaper servers with less hassle.
The Problem
My first real job was at Atlassian. When I started the company was still deploying some hosted customers on VMware clusters. Over the years, we transitioned to an in-house private cloud and then onto AWS. Since then I’ve worked in various roles as a consultant and most recently spent four years at a SaaS fintech deploying almost entirely to the cloud.
As a software engineer, the benefits of the cloud are obvious. I’m empowered to consume the infrastructure I need to deliver value on-demand, without having to spend weeks or months having it provisioned. But this is a question of organisation design as much as anything – I don’t care if I’m hitting an internal API to provision a database, or AWS. The big public cloud players have played a trick - here’s a new model for how to deploy applications, but to take advantage of it you have to deploy them with us.
At one point we were looking at a particularly heavy service running in AWS. The cost was enough of a problem that we were considering deploying a private cloud for it. But the proposal never got past the ideation phase because the quality of the tooling available for private clouds is stuck in the past century, and the cost of building it ourselves would have negated the benefit. I don’t accept that Jeff Bezos owning the computer has to be the only way to have nice things.
I’ve been working in IT Managed Services space for the last few years. You probably know of MSPs as the guys who fix the printers and helps the accounts department with lost desktop shortcuts, that’s us. Optimisation in MSP-land is about reducing variation or nuance in the environment, even between customers. The more things are the same the easier it is to ensure they keep working. We had rules about everything down to the patch cables. Scale through standisation.
We specialised in manufacturing, transport, and other light industrials. One of our customers produced 100k+ slices of banana bread every shift and the smell of the left-over banana crates will never leave me. Another processed coils of steel into useful shapes for constructing buildings using high speed cut-and-bend machines; the sort of place a Final Destination movie could be shot.
The recurring theme here is that we always had a need for On-Prem compute. These sorts of businesses require long-lived, stateful Virtual Machines with direct network access to the equipment they manage. You could call it IoT Edge for Process Automation, but really, it’s a Windows 2000 box filled with [literal] spiders.
VMware’s ESXi is still the standard in a lot of this world but it’s certainly showing its age. You’ve still got to use a hardware RAID controller whilst monitoring or backup require a third-party product. To make matters worse each customer needs their own vCenter deployment for management, which then needs maintenance and backup. Over a hundred customers it takes roughly 400 VMs just to manage the actual value-creating workloads.
In short, those servers aren’t going anywhere and managing them is a pain. I wanted something that scaled horizontally across customer boundaries. Ideally something my junior colleagues could handle whilst ensuring that every deployment remained the same.
Version 0.1
Version 0.1 was rough, Richard put most of it together in between our games of Satisfactory and I built-out up the frontend in an afternoon. There may still be a Fiscit joke or two in the current UI if you know where to look. It consisted of a monolithic application server that handled both commands (Start/Stop) and console connection relay (VNC).
The Hypervisor itself was a Debian install with KVM/QEMU, Libvirt, and a management agent written in nodeJS. Everything was installed and configured by hand. Everything was tested on a junk Lenovo M900 which still runs in our test environment. We’ll probably have to frame the thing the day it gets decommissioned.
Rewrite in Rust, Hardware Shenanigans, and Rolling Our Own Image
I had been experimenting with Rust for small side-projects for years, but had not had the opportunity to use it for a real project. Over the course of a few weeks I re-wrote the management agent in Rust. Coming from primarily writing Java, I’m really impressed with how expressive the type system is, and how effective it is at catching mistakes. I’ve found async Rust to be much more ergonomic than async programming in Java.
Having a fully-automated build process for all our software artifacts is a hard requirement, so hand-building Debian images was not a viable long-term strategy. We also wanted the base operating system to be as simple and light as possible. After some research, we settled on Alpine Linux. A default clean Alpine install has ~6 processes running depending on how you count, and they provide a convenient script intended for bootstrapping VM images that took only minimal customization to get running on real hardware. Unfortunately no-one has written a complete “how-to-build-a-working-Linux" guide, so this involved comparing the image produced by the script to a clean install. This process was not entirely error-free – for example, Alpine skips including the nvme module in the initramfs if you’re not installing to an NVMe disk, so the first versions of our image couldn’t boot from NVMe.
On the topic of hardware compatibility, we were lucky enough to inherit the full range of Dell, HPE, Cisco, and Lenovo servers from my former-MSP. This makes our test lab broad, but doesn’t solve the fact it’s now located in the kitchen- making lunchtime a hot and loud activity.
Thankfully server compatibility hasn’t been an issue so far. Users do keep throwing curveballs at us though. Gallium does not work on a Lenovo L13 Laptop. We don’t know why [yet].
Once the basics were solved, we applied a raft of customizations – making the image bootable in both BIOS and UEFI mode, using a read-only squashfs volume for the root filesystem, adding scripts to auto-generate network configuration, etc.
The end result is a 700MB base image that boots in seconds – even from a spinning hard disk - and has a minimal memory footprint. Updates are done by downloading a new squashfs volume and booting from that next reboot.
Cloud-init (Which an exceptionally funny name if you’re British)
We’d now built a version that performed most of the VM lifecycle, but it was basically a worse version of ESX. No one wants to click through an installation wizard to deploy an OS in a VM. We wanted the experience to be like AWS where you can just select an image, set some credentials, and provide a config script. We knew all the major Linux distros provided cloud-ready images that could be provisioned with Cloud-init. We wanted to just use those images without having to roll an agent into each one.
Cloud-init supports a variety of configuration mechanisms. The simplest is to generate an ISO file with the desired configuration files and present it to the VM as a virtual CD. Our first implementation used this approach and we quickly discovered a number of shortcomings. It’s tricky to provide a new configuration while the VM is running. Further, it presented a security issue – we expose the option to set a password for the default user, and there’s nothing preventing an unprivileged user who has access to the VM from reading the password hash from the cloud init CD. We experimented with various workaround to this – we tried ejecting the CD to signal to the hypervisor that cloud-init was done, but it turns out that most cloud images don’t ship with an eject binary for some reason. At one point we experimented with injecting an eject binary through cloud-init, but at this stage it was clear that we needed a better approach.
Cloud init also provides for fetching configuration from the network, from a URL read from the virtual serial number. We considered exposing a unique one-time URL from a web service, but this won’t work in any scenario where the VM can’t reach the internet.
Really what we wanted was the same thing you have in the cloud – a metadata service reachable from the VM, over a link-local IP address. Implementing this was definitely one of the most interesting challenges so far. For each virtual NIC we spawn a new Linux network namespace, bind to a link-local address, bridge it to the VM’s NIC, and set up network filter rules to ensure they can both talk to each other. The next challenge was link-local addressing – Windows and macOS automatically assign a link-local IPv4 address before DHCP completes, but Linux does not. To solve this we made the metadata service available over both IPv4 and IPv6 – Linux will configure a link-local IPv6 address as long as the interface is up and IPv6 is enabled at all.
(One fun aside – during development and before I had written the filter rules, I noticed my metadata service was seeing requests to a URL that wasn’t one of the standard endpoints used by cloud-init, from an IP not associated with any of my VMs. Some sleuthing later, it turned out this was an Azure endpoint, and the requests were coming from the Copilot plugin on my laptop)
This solution is still not perfect – it turns out cloud-init's generic datasources don’t look for the newer network configuration formats over the network. We’re still exploring what to do here – we may provide network configuration through a config drive, we may emulate one of the existing datasources, or we may implement our own datasource.
The Windows approach is a little more complex again. Things would be easy if we could just provide the machine image unlicensed. The planned solution is to take the customer supplied media and use Microsoft’s own automated build tools to inject Cloudbase-init alongside the required VirtIO Drivers. Once prepared the resulting machine image can be kept up to date with Windows Update offline servicing. Meaning that whenever the User provisions a new Windows VM it will come fully patched.
This may result in a process somewhere that spends all day patching thousands of copies of the same OS but we’ll deal with that when it’s a problem.
What Next
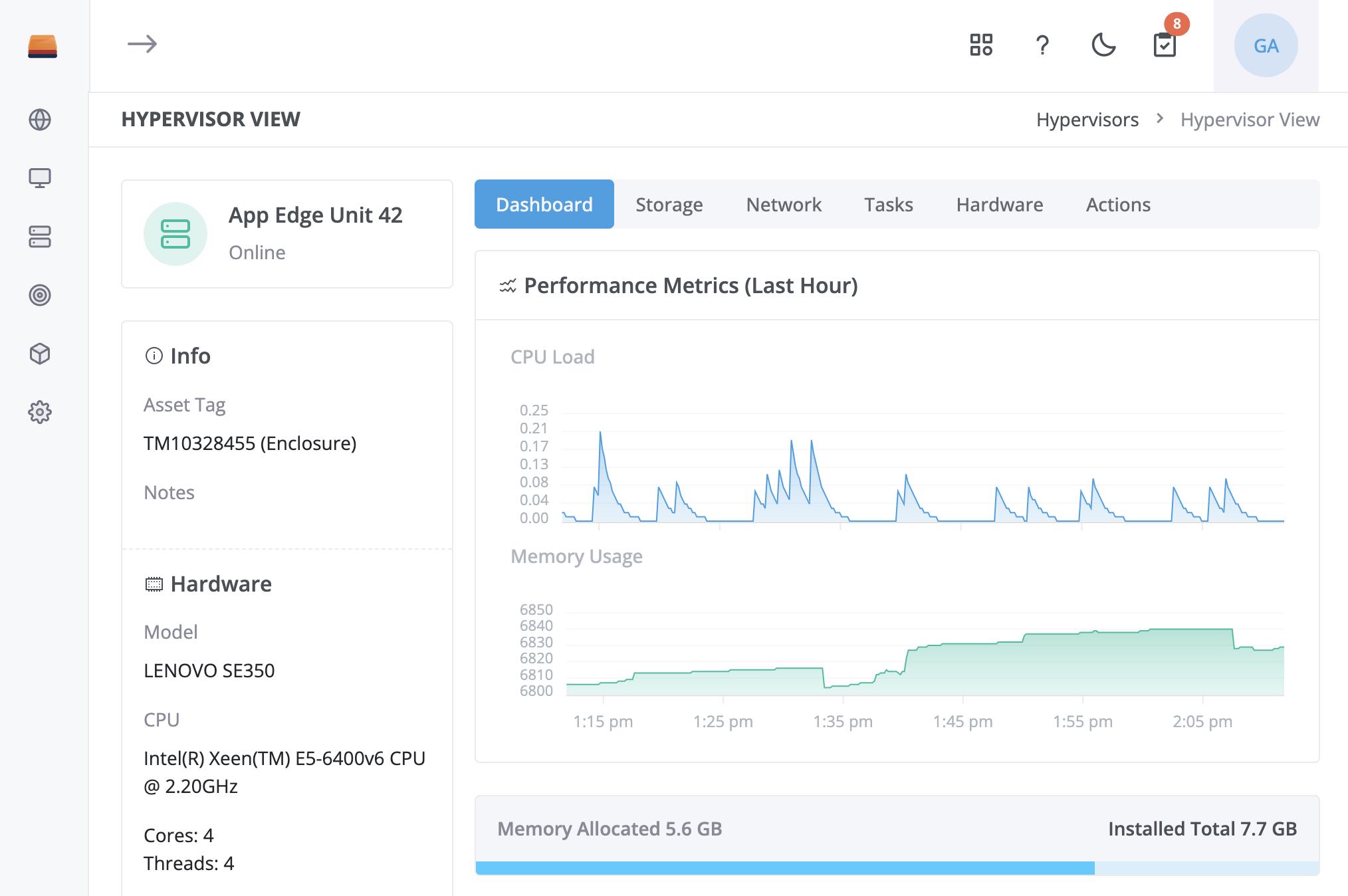
We’re reached the point where we have stable product that provides for most of our early use-cases. Quirky hardware aside, the bulk of new Users get from signup to booting a hypervisor and running a VM in ~18 minutes.
A key area we’d like to explore is how hypervisors within the same customer deployment communicate with each other. Today we build an isolated IPv6 tunnel over Wireguard to our relays to perform certain tasks. Future releases will build those tunnels to other servers so that, NAT permitting, moving a VM from one server to another doesn’t have to go via a relay.
Building these sorts of “works, no matter where” solutions is part of what we think will set the product apart.
Support for IaaC tooling is a must – and we plan to build integrations for the most popular platforms. But I think there’s a larger opportunity here – it's easy to forget that most of the world still isn’t doing it. I’ve experienced this first-hand working in platform teams – engineers focused on delivering business value don’t necessarily want to also learn an alphabet soup of IaaC tools.
Longer term, I’d like to improve the debugging story. Often in the cloud an instance is just hung, so we just reboot or reprovision it. Figuring out why ranges from not economically viable to impossible. Hell, sometimes I just want to grab a log file from an unbootable instance before I blow it away, and on AWS that’s several steps.
We obviously see a scenario where we need to support containerisation. There are already some very good options for Docker/k8s on the edge which already run very well on-top of Gallium. Integration is one possible option.
We’ve seen a fascinating use case around deploying GPUs in Factories to do Computer Vision for defect detection. The CV model/processor itself is containerised and at the end of a build pipeline that updates often.
What’s less obvious is how to deal with containers with stateful workloads. You’d probably want those to replicate to a Gallium server on another site. I’ve pulled a lot of servers out of the wreckages of flooded, burnt, or accidentally demolished buildings. The Edge is a risky place for a lone server.